<style type="text/css">
<!--
@page { margin: 2cm }
P { margin-bottom: 0.21cm }
PRE.western { font-family: "DejaVu Sans Mono", monospace }
PRE.cjk { font-family: "DejaVu Sans", monospace }
PRE.ctl { font-family: "DejaVu Sans Mono", monospace }
-->
</style>
浅析linux内核内存管理之高端内存
作者:李万鹏
进程可以寻址4G,其中0~3G为用户态,3G~4G为内核态。如果内存不超过1G那么最后这1G线性空间足够映射物理内存了,如果物理内存大于1G,为了使内核空间的1G线性地址可以访问到大于1G的物理内存,把物理内存分为两部分,0~896MB的进行直接内存映射,也就是说存在一个线性关系:virtual address = physical address + PAGE_OFFSET,这里的PAGE_OFFSET为3G。还剩下一个128MB的空间,这个空间作为一个窗口动态进行映射,这样就可以访问大于1G的内存,但是同一时刻内核空间还是只有1G的线性地址,只是不同时刻可以映射到不同的地方。综上,大于896MB的物理内存就是高端内存,内核引入高端内存这个概念是为了通过128MB这个窗口访问大于1G的物理内存。
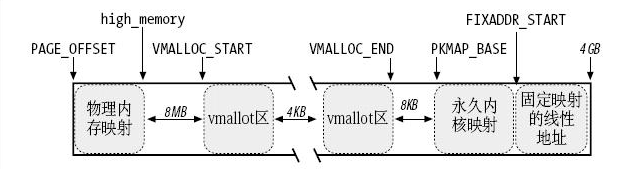
上图是内核空间1G线性地址的布局,直接映射区为PAGE_OFFSET~PAGE_OFFSET+ 896MB,直接映射的物理地址末尾对应的线性地址保存在high_memory变量中。直接映射区后边有一个8MB的保护区,目的是用来"捕获"对内存的越界访问。然后是非连续内存区,范围从VMALLOC_START~VMALLOC_END,出于同样的原因,每个非连续内存区之间隔着4KB。永久内核映射区从PKMAP_BASE开始,大小为2MB(启动PAE)或4MB。后边是固定映射区,范围是FIXADDR_START~FIXADDR_TOP,至于临时内核映射区是永久内核映射区里的一部分,在后边会做详细解析。
下边来详细介绍高端内存的三种访问方式:非连续内存区访问,永久内核映射,临时内核映射。
非连续内存区访问:
非连续内存区访问会使用一个vm_struct结构来描述每个非连续内存区:
vm_struct与vmalloc()分配的非连续线性区有如下关系:

下边来看非连续内存区的分配,分配调用了vmalloc()函数:
flags标志中设置了从high memory分配。
调用get_vm_area()分配描述符和获得线性地址空间,get_vm_area()函数在线性地址VMALLOC_START和VMALLOC_END之间查找一个空闲区域。步骤如下:
1. 调用kmalloc()为vm_struct类型的新描述符获得一个内存区。
2. 为写得到vmlist_lock()锁,并扫描类型为vm_struct的描述符链表来查找线性地址一个空闲区域,至少覆盖size + 4096个地址。
3. 如果存在这样一个区间,函数就初始化描述符的字段,释放vmlist_lock锁,并以返回这个非连续内存区的起始地址而结束。
4. 否则,get_vm_area()释放先前得到的描述符,释放vmlist_lock,然后返回NULL。
调用map_vm_area()建立页表与物理页之间的映射:
map_area_pud也就是反复调用map_area_pmd来填充各级页目录,页表。map_area_pte()的主循环如下:
调用set_pte设置将相应页的页描述符地址设置到相应的页表项。非连续内存区的释放:
需要注意的是,map_vm_area()并不触及当前进程的页表。
非连续内存区的释放:
调用vfree()函数:
__vunmap()调用remove_vm_area(),执行与map_vm_area()相反的操作,最终调用到了unmap_area_pte():这里调用ptep_get_and_clear()宏将pte指向的页表项设为0。
注意,在调用vmalloc()时建立的映射是在物理内存和主内核页表之间的,并没有涉及到进程的页表。当内核态的进程访问非连续内存区时,缺页发生,因为该内存区所对应的进程页表中的表项为空。然而,缺页处理程序要检查这个缺页线性地址是否在主内核页表中。一旦处理程序发现一个主内核页表含有这个线性地址的非空项,就把它的值拷贝到相应的进程页表项中,并恢复进程的正常执行。在调用vfree时,与vmalloc()一样,内核修改主内核页全局目录和它的子页表中相应的项,但是映射第4个GB的进程页表的项保持不变。unmap_area_pte()函数只是清除页表中的项(不回收页表本身)。进程对已释放非连续内存区的进一步访问必将由于空的页表项而触发缺页异常。
永久内核映射:
永久内核映射使用主内核页表中一个专门的页表,其地址存放在pkmap_page_table变量中,页表中的表项数由LAST_PKMAP宏产生,因此内核一次访问2MB(启动PAE)或4MB的高端内存。该页表映射的线性地址从PKMAP_BASE开始,pkmap_count数组包含LAST_PKMAPGE个计数器,pkmap_page_table页表中每一项都有一个。
计数器为0
对应的页表项没有映射任何高端内存页框,并且是可用的。
计数器为1
对应的页表项没有映射任何高端内存页框,但是它不能使用,因为此从他最后一次使用以来,其相应的TLB表项还未被刷新。
计数器为2
相应的页表项映射一个高端内存页框,这意味着正好有n-1个内核成分在使用这个页框。
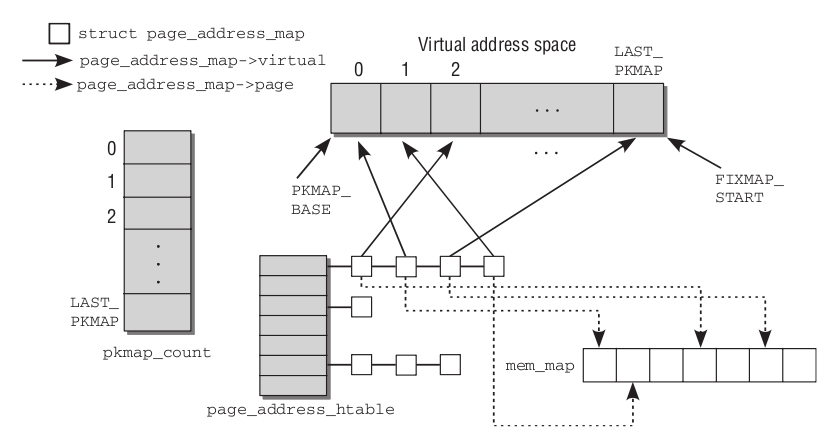
为了记录高端内存页框与永久内核映射的线性地址之间的联系,内核使用了page_address_htable散列表,该表包含一个page_address_htable结构,该表包含一个page_address_map数据结构,用于为高端内存每一个页框进行当前映射。而该数据结构还包含一个指向页描述符的指针和分配给该页框的线性地址。page是一个指向全局mem_map数组中的page实例的指针,virtual指定了该页在内核虚拟地址空间中分配的位置。为了便于组织,映射保存在散列表中,结构中的链表元素用于建立溢出的链表,以处理散列碰撞。散列表为page_address_htable,散列函数是page_slot,根据page实例确定页的虚拟地址。如果page是在普通内存中的,则根据page在mem_map数组中的位置计算。
进行永久内核映射需要调用kmap()函数:
kmap函数只是一个前端,用于确定指定的页是否确实在高端内存域中。首先判断是不是高端内存,如果不是高端内存就调用page_address直接返回page对应的线性地址,0~896MB的是直接映射,也就是在kernel初始化的时候映射已经建立好了,之后直接访问就行了。而高端内存需要自己建立映射,然后才能访问。如果是高端内存则将工作委托给kmap_high:
首先获得需要映射的page对应的线性地址,从page_address_htable中进行查找,如果已经映射过了肯定不为空,如果没有映射过则执行map_new_virtual进行映射。注意这里进行的pkmap_count加一操作,后边会提到。
内核将上次使用过的页表项的索引保存在last_pkmap_nr变量中,避免了重复查找。如果找到计数器为0的,则获得这个页表项对应的页表的线性地址,填充相应的页表项,计数器为1。这里产生一个问题,刚才不是说为1代表“对应的页表项没有映射任何高端内存页框,但是它不能使用,因为此从他最后一次使用以来,其相应的TLB表项还未被刷新。”,确实是这样,看看调用map_new_virtual函数的kmap_high函数,在这里对pkmap_count进行了再次加一。 kmap会导致进程阻塞,所以永久内核映射不能运行在中断处理程序中和可延迟函数的内部。所以这里kunmap首先判断是不是在中断上下文中,如果不在中断上下文并且不再高端内存,则将工作委托kunmap_high。如果有计数器为1的表项,而且有等待的进程,则唤醒进程。如果有进程被阻塞那么肯定没有计数器为0的表项了,所以从map_new_virtual中start标号的地方开始执行,应该会把表项遍历一圈,此时肯定会遇到last_pkmap_nr为0的情况,此时就可以调用flush_all_zero_pkmaps()函数来寻找计数器为1的表项,将其清零,解除映射,并刷新TLB。可以看到kunmap并没有解除映射,并刷新tlb,这里仅仅是将表项的计数器减一。为什么要这样做呢?看一下kmap_high函数中,判断了一次是否已经映射了,如果映射了就把表项的引用计数器加一,也就是说如果调用过kunmap使计数为1了,此时又变成2,又可以进行访问了,不用重新填充页表,刷新tlb等。
分享到:




相关推荐
Linux常见驱动源码分析(kernel hacker修炼之道)--李万鹏 李万鹏 IBM Linux Technology Center kernel team 驱动资料清单内容如下: Linux设备模型(中)之上层容器.pdf Linux设备模型(上)之底层模型.pdf Linux...
常见驱动源码分析( LINUX kernel hacker修炼之道)-李万鹏
常见驱动源码分析(kernel hacker修炼之道)
如果刚刚对linux的kernel有兴趣,想了解点什么的话,请先看看此书吧,她风趣幽默的介绍了linux的发展趣事,让你开心快乐之余慢慢领会linux的魅力,让你了解学习掌握kernel的方法。其中的很多建议经过我的实践和摸索...
国嵌的笔记 非常的不容易 里面驱动 包括USB LCD 文件系统 内存管理有非常详细 的记录
Linux PCI驱动牛人写的论文,有一定参考价值
有关hacker 的文章和资料分享给大家
渗透测试教程资料
hacker-history.pdf hacker-history.pdf
Algorithm-HackerRank-Solutions-In-Scala.zip,在scala中解决hackerrank的挑战,算法是为计算机程序高效、彻底地完成任务而创建的一组详细的准则。
黑客入门教材,理论结合实践,通俗易懂。为读此书,先学英文也值得。
Process Hacker是一款功能丰富的系统程序,比windows自带的任务管理器功能更强大。用户只要借助该程序就可以方便,快捷地查看相关进程的速度,内存,及模块等等,除此,还可以对相关的进程进行管理工作。
HackerRank-Interview-Preparation-Kit-master.rar
Resource Hacker 可以被用来: 1. 查看 Win32 可执行和相关文件的资源 (*.exe, *.dll, *.cpl, *.ocx),在已编译和反编译的格式下都可以。 2. 提取 (保存) 资源到文件 (*.res) 格式,作为二进制,或作为反编过的译...
Hacker 2012 - Final Transfer Readme =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=- Thank you for downloading Hacker 2012! Registration ------------------------------------ If you like the game, ...
Resource Hacker是一款免费查看,修改,添加,删除和重命名,提取Windows可执行文件和资源文件的资源替换工具,Resource Hacker反编译工具是相当于eXeScope的反编译工具,并且有很多方面比eXeScope反编译还强的软件.
Process Hacker是一款强大的系统进程管理工具,开源,并且还可以显示CPU、GPU、IO、内存等相关使用信息。 官网地址:https://processhacker.sourceforge.io/ git地址:...
Process Hacker是一款针对高级用户的安全分析工具,它可以帮助研究人员检测和解决软件或进程在特定操作系统环境下遇到的问题。除此之外,它还可以检测恶意进程,并告知我们这些恶意进程想要实现的功能。 Process ...
Process Hacker是一款强大的系统进程管理工具,开源,并且还可以显示CPU、GPU、IO、内存等相关使用信息。 官网地址:https://processhacker.sourceforge.io/ git地址:...
rails-hackernews-reddit-producthunt-clone, 黑客 news/reddit/social 链接分享网站 用 Rails 构建 Rails 上的 Reddit-Hackernews-ProductHunt克隆演示 这是一个 readme.md的Ruby on Rails 应用程序,模仿了 Hacker...